Artificial Neural Networks - Inspired by functioning of biological Neurons
Many of the things in science and specifically Machine learning are influenced by life we see around us. One of the most complex things around us is we our self and how our various parts works. If we would think about the most complex part in human body, one thing that pops up is " central nervous system".
There are various questions around the working of Brain - how human brain is able to process huge amount of data and take actions on the basis of learning made in the past ?, How brain is able to make decisions taking the holistic view of the situation ? How we are able to learn from the environment around us. Definitely, nature has made working of brain very complex and still lot of research is pending to understand it in totality.
Background :
Examination of human central nervous system inspired the concept of Artificial Neural Networks.
Warren McCulloch & Walter Pits created a computational model for neural networks based on mathematics & algorithms called threshold logic. This study was further split in two parts - one part concentrated on biological aspect of it in brain and another part concentrated on the application of neural networks to artificial intelligence.
Artificial Neuron :
Basic building block of artificial neural network is artificial neuron. Its design and functionalities is influenced by natural biological neuron which makes up our central nervous system. Let us see the biological neuron structure and relate it to the creation of artificial neuron.
 |
| Source : Wikipedia |
Biological neuron has below 3 main parts :
1) Dendrite : These are thin structures that arise from cell body and help in getting the information to neurons.
2) Soma : These are the cell body which processes the information.
3) Axon : They are also known as nerve fibers which passes information to different neurons, muscles & glands.
Let us represent the artificial neuron and compares it with biological neuron parts dendrite, Soma & Axon.
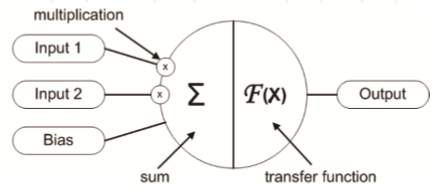
- Dendrite - Inputs : As dendrites passes the information to neurons, the information comes to artificial neurons via inputs which are weighted.
- Soma - Body of Artificial neuron : As Soma processes the information in case of biological neuron, body of artificial neuron summarizes the weighted inputs and apply the transfer function.
- Axon- Output : As Axon takes the information processes by Soma to other neurons, muscles & glands, output, similarly outputs transfer the information to other artificial neurons.
Artificial neuron has three simple sets of rules as shown above - multiplication, summarization and activation. At the entrance of artificial neurons all inputs are weighted, then these weighted inputs and bias are summarized in the central part and at last these sum of weighted inputs and bias is run through the transfer function and output is provided.
Mathematically this artificial neuron can be summarized as :

The major unknown variable of the model is the transfer functions. This transfer function is chosen on the basis of the problem we are solving. Step function, linear function and signoid functions are generally used in most of the cases. Mostly artificial neurons exploits the non linearity and uses sigmoid functions.
Artificial Neural Networks :
Some of the characteristics of Artificial Neural Networks that mimic the properties of the biological neural network are:
- They exploits the non linearity - They exploit non linearity by interconnection of non linear neurons.
- They have Input-Output Mapping - They have learning capability both "with"(supervised) a teacher as well as "without" (unsupervised) a teacher.
- They are Adaptive - They can adapt to the changes in the surrounding environment
These interconnected artificial neurons have the capability to solve various real life problems by exploiting the above properties. Below figure shows how these neurons could be interconnected in three different layers - Input, hidden and output layer.
The steps involved to start using the interconnected neurons is to :
- First define the topology or architecture and fine tune that in which way these neurons could be interconnected to form network.
- Teach (train) it to solve the given type of problem
Artificial Neural Networks Topology
There are two basic ways in which artificial neurons could be connected to each other
1) Feed Forward topology
2) Recurrent Neural Network Topology
In the case of Feed forward topology, the information flow from input to output in only single direction(directed acyclic graph) whereas in case of Recurrent Neural network topology, the information can flow in both the directions (directed cyclic graph). The main advantage of RNN is that they can use their internal memory to process sequence of input. Below figure shows both these topologies.
 |
| Feed Forward & Recurrent Neural Network Topology |
Different Topology of Neural Networks :
- Fully Recurrent Artificial Network - This is the most basic topology of recurrent neural network where every basic unit is connected to every other unit in the network.
- Hopfield Artificial Neural Networks - This is the type of RNN where one or more stable target vector is stored. This topology has only one layer with each neuron connected to every other neuron with restriction that no unit has connection to itself & connections are always symmetric. This topology can be used for various pattern recognition problems as it has the memory of target vectors which can be recalled when given similar vector that acts as the cue.
- Elman & Jordan Artificial Neural Networks: These topology is also referred as Simple Recurrent Network. This is simple three layer artificial neural network that has back loop from either output layer or from hidden layer to input layer through context unit. In case of Elman, back loop is from hidden layer to input layer whereas in case of Jordan back loop is from output layer to input layer. As Elman network is able to store information, it is able to generate temporal and spatial patterns.
- Long Short Term Memory : As the name suggests, in this kind of topology it can remember the value for any length of time and therefore network can process, classify and predict time series with very long time lags. The remembering process is controlled by gates which determine when the input is important to remember, how long the input value to be remembered and when this value to be released to the output.
- Bi Directional Artificial Neural Network : Bi-ANN were invented to increase the amount of input information that can be referred. These consist of two individual interconnected artificial neural networks. These are very useful for the type of prediction where context of the input is important eg - handwriting recognition where knowledge of the current letter can be improved by having details of letter before and after the letter. These are very useful to predict complex time series .
Below is the representation of different topologies of Neural Network :
 |
| Fully Recurrent, Hopfield, Elman Recurrent Neural Network Topology |
 |
| Jordan, Bi Directional & Long Short Term Memory Recurrent Neural Network Topology |
Learning :
Once the topology is defined for the Neural network, next step is to train them to solve the given type of problem. One of the important characteristic that artificial neural networks mimic from biological neuron in the brain is their ability to learn. in ANN the learning is mimicked by setting the weights of the connections between the different neurons using algorithms to get the desired output.
The three major learning paradigms that can be used to train any artificial neural network are as follows :
- Supervised Learning : This is a technique where the desired output is also provided with the input while training the algorithm. The weights of the network is adjusted in such a way to come close to the desired output. Various steps are involved to solve the given problem using supervised learning - Determine the training examples, gather the training data that describe the given problem, describe gathered data set in form understandable to a neural network, do the learning and as the last step validate the output by performing tests.
- Unsupervised Learning : In this technique set of unlabeled inputs are given without setting some relationship between this data. Artificial neural network tries to find some relationship between this data. These are used to solve mostly the estimation problems such as statistical modelling, compression etc. Mostly self organizing maps are used for unsupervised learning algorithms.
- Reinforcement Learning: Reinforcement learning is influenced by the behavioral psychology. It is something how the natural learning works for example kid knows which action to perform again to make others praise/clap for him (reward). In this type of learning the data is not generally given but generated by interaction with the environment. The aim here is to maximize the reward by trying out different options. Reinforcement learning is mainly suited for problems which include long term versus short term reward trade off. Some of the problems it is applied to are robotics, game theory, telecommunications etc.
Usage of Artificial Neural Networks :
One of the best characteristic of Artificial Neural Networks is their ability to learn form the environment. This is similar to how our central nervous system or brain works. In artificial neural networks we give input and output to the neural networks and it works on to create the function to generate the optimum output after learning. This is the reason there are good usage of Artificial Neural Networks in the fields which our brain does very good like facial recognition, handwriting recognition, game theory etc.
One thing to note is that selection of particular topology is governed by the type of problem we are solving and the data set available for it. Also complexity of the model that we are choosing to solve the given problem plays the major role. Using very simple model can give poor result and using very complex model to solve simple problem can cause issues during the learning process.
One of the usage of Artificial Neural network is for modelling and representing natural language. Natural language processing has the core usage in many industries like search engine, email categorization, Pharma Co vigilance etc. Wait for my next blog to get the glimpse of usage of Neural Networks for Natural Language Processing.
References :
- Introduction to the Artificial Neural Networks By Andrej Krenker, Janez Bešter and Andrej Kos.
- Wikepedia
- http://www.theprojectspot.com/